A new era for high-throughput proteomics

Several factors are driving this paradigm shift
• A growing culture of open collaboration and information sharing
• Big-data analysis tools
• Access to very large, well-characterized biobank sample collections
• Advances in proteomics with the ability to provide reliable data at scale
Genomics has not had the transformative effects on therapeutic medicine originally envisaged.
Empower genomics with proteomics - “proteogenomics”
Technical challenges have been overcome by next-generation proteomics
 Identifying robust drug targets with disease causality
Identifying robust drug targets with disease causality
1. Selecting the right drug target
Identifying proteins that plays major causal roles in specific diseases is a critical early milestone for any therapeutic development program. This enables the selection of robust drug targets based on sound molecular evidence.
A mistake in target selection could be disastrous and costly further down the long and extremely expensive drug development process. Genetically informed target selection has been shown to double the likelihood of a drug development program, but genetics alone can’t determine causality for a given protein.
Understanding whether phenotype/protein expression associations represent a cause or consequence of disease is far from trivial in human clinical studies, but the unique advantages of combining genomic and proteomic data can provide unique insights into the likely causal roles of any given protein in a specific disease.
2. Determining causality using cis-pQTLs and Mendelian Randomization
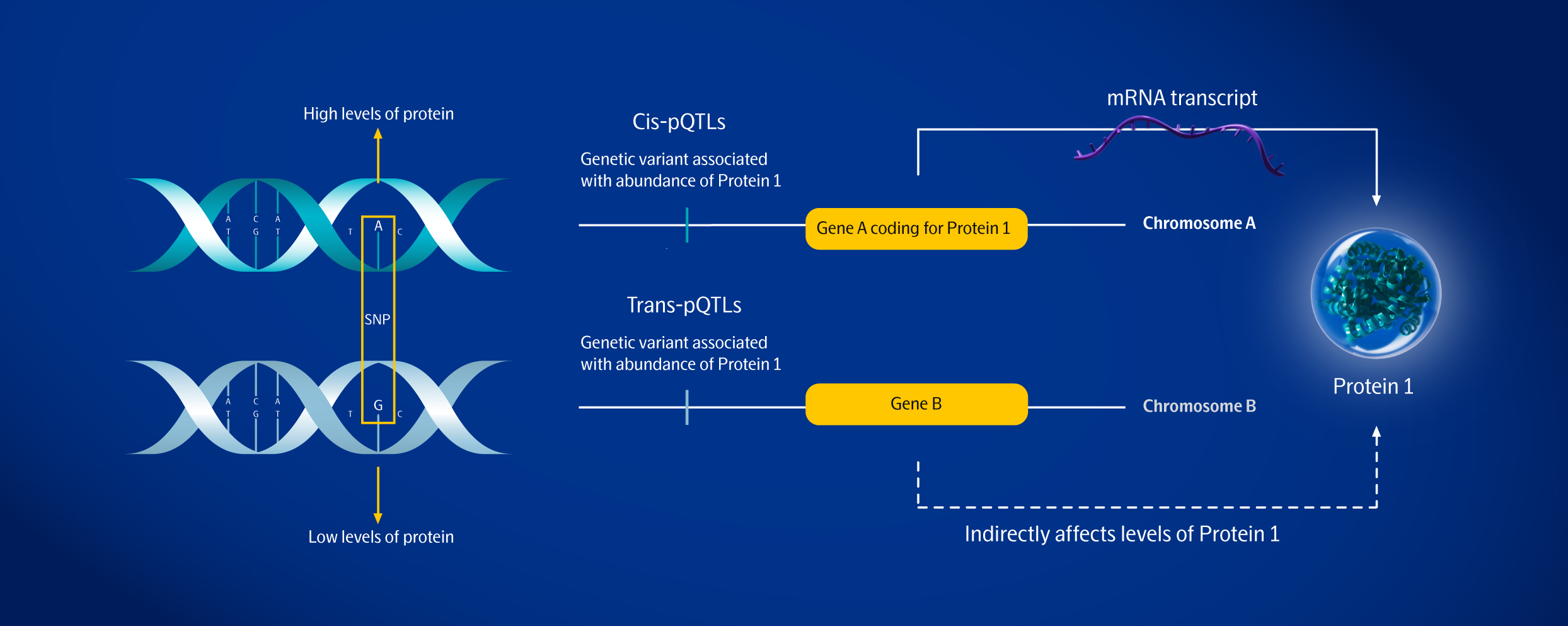
As previously described, pQTLs are locations in the genome that contain one or more genetic variants associated with circulating protein levels. Genetic variants that are close to, or within the same gene that makes the protein are called cis-pQTLs, while those located distally to the protein-coding gene are called trans-pQTLs. The latter can be valuable in identifying novel regulatory pathways, whereas cis-pQTLs are of special interest because the variant is highly likely to affect protein levels by direct regulation of its gene.
See the full size image
| In terms of drug target selection, cis-pQTLs can be used as genetic instruments in a statistical method called Mendelian Randomization (MR), which can test the hypothesis that the protein molecule plays a causal role in disease risk by statistical testing of the genetically-regulated protein levels in relation to the biological outcome. The adoption of this approach by the scientific community has led to increasingly large-scale initiatives and collaborations.
SCALLOP, for example, is an independent, collaborative framework for the discovery and follow-up of genetic associations with proteins for researchers generating data using the Olink platform. The aim of the SCALLOP consortium is to identify novel molecular connections and protein biomarkers that are causal in diseases, and to date, 35 PIs from 28 research institutions have joined the effort, which now comprises summary level data for almost 70,000 patients and controls from 45 cohort studies. |

Article
Proteomics can complement genomics to identify new regulatory pathways, biomarkers, and drug targets, according to a panel of proteogenomics experts.
Interview
Population scale proteomics accelerates the search for effective new drug targets
Dr. Chris Whelan (Chair and Principal Investigator of the UK Biobank – Pharma Proteomics Project) discusses how data from the UK Biobank – Pharma Proteomics Project has revealed new insights into associations between gene variants and protein concentrations enabling new causal biomarkers for diseases to be identified as well as new drug targets with higher probabilities of success.
Watch the interview
 Maintaining specificity in multiplex protein assays
Maintaining specificity in multiplex protein assays
Specificity and why it matters.
Proteomic technologies that enable the measurement of thousands of proteins at population scale have the potential to transform our understanding of human biology and drive future healthcare development. Gaining actionable insights and a deeper understanding of disease biology can only be achieved, however, if scientists can be confident that they are measuring the correct proteins.
Historically, protein detection methods suffered from an increasing level of cross-reactivity and non-specific signals as the multiplexing level increased. Olink’s PEA technology and exceptionally thorough, transparent validation procedures now ensure, however, that each assay robustly detects its intended protein target, even when measuring thousands of proteins simultaneously in complex biological samples.
This is important, as the misidentification of proteins can cause serious issues:
- Misdirection of research progress due to incorrectly identified biomarkers
- Erroneous associations of biological pathways with phenotypes and disease outcomes
- Wasted time and resources resulting from misinformed study planning
- Selection of invalid proteins or pathways as therapeutic targets, leading to expensive failures in drug development programs
Olink Proximity Extension Assay
Designed for specificity, validated for quality
Our dual-recognition, DNA-coupled technology delivers industry-leading specificity, eliminating wrong targets, misinterpretation and wasted resources. Every assay undergoes a rigorous validation process, ensuring quality data you can trust.
For each protein target, two oligonucleotide-coupled antibodies (PEA probes) must bind in close enough proximity to enable the oligos to hybridize and form a unique DNA template for detection by NGS or qPCR. This dual antibody recognition and hi-fidelity DNA-coupled measurement mean that PEA is able to provide truly exceptional readout specificity. This overcomes the problems normally associated with multiplexed immunoassays, since any potential antibody cross-reactivity will not contribute to a detection signal. This degree of specificity is a hallmark of PEA.
At any scale
While PEA technology maximizes readout specificity in high multiplex analysis, Olink has also developed a rigorous approach to assay QC and validation to ensure that only the highest quality assays with exceptional specificity are selected for inclusion in our products. The 5,400+ protein assays in the latest Olink® Explore HT platform for high-throughput protein biomarker discovery, for example, each went through an exhaustive 3-step, 15-factor analytical verification process to ensure that every one meet’s Olink’s exacting standards of technical performance and specificity.
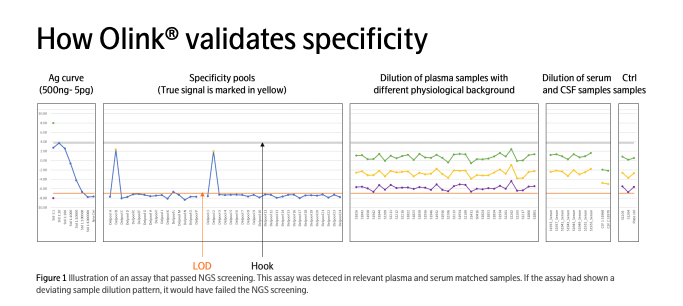
Technical and biological validation of PEA specificity
Our white paper, “PEA: Exceptional specificity in a high multiplex format“, explains how the specificity of Olink assays is achieved and tested, and cites numerous examples where scientists have shown technical or biological validation of correctly identified proteins.
These include:
- orthogonal validation of key results using other technologies (e.g. ELISA)
- cis-pQTLs consistently reported for a high proportion of proteins investigated in Olink studies, providing compelling genetic evidence for correct protein identification
- comparisons with other multiplexed affinity-based technologies showing a higher proportion of genetically validated proteins using Olink
PEA video
Olink’s PEA technology – the movie
This short video overviews the Proximity Extension Assay (PEA) technology that lies behind our Olink Explore and Olink Target 96/48 platforms, with NGS or qPCR readout, respectively. The animation explains how our innovative dual recognition, DNA-coupled methodology provides exceptional readout specificity, enabling high multiplex, rapid throughput biomarker analysis without compromising on data quality.
Watch video

specificity
Developed for specificity,
validated for quality
Our dual-recognition, DNA-coupled technology delivers industry-leading specificity, eliminating wrong targets, misinterpretation and wasted resources. Every assay undergoes a rigorous validation process, ensuring quality data you can trust.
Watch video
White paper
PEA: Exceptional specificity in a
high multiplex format
This white paper shows how the accuracy of the Olink® Proximity Extension Assay (PEA) technology has been validated regarding recognizing the intended target protein. It shows how Olink tests specificity and how Olink’s customers have validated the PEA technology using orthogonal methods.
Read more
 Scaling up proteogenomics to population-scale studies
Scaling up proteogenomics to population-scale studies
High-throughput proteomics is now a reality
The preceding sections showed how proteomics can empower genomics to make actionable and impactful discoveries that can drive future drug development, and how PEA has overcome many of the technical limitations of previous proteomic technologies to enable measurement of thousands of proteins with exceptional specificity.
Population-based, multiomic studies that can generate the statistical power to address highly complex biological questions, investigate rare diseases and account for genetic diversity among populations also require very large-scale approaches that measure many thousands of proteins.
Olink’s high-throughput proteomics solutions have been employed in ever larger population studies and can now provide the scalability that the research community has been asking for. As an example, Olink Explore HT can now run a 50,000 sample project in just 12 weeks using two sample handling/NGS instrument lines.
The SCALLOP consortium
As described in the section above, identifying robust drug targets with disease causality, SCALLOP is an independent collaborative initiative where research groups with both genetic data and proteomic data generated using Olink panels collaborate and share the findings from their different cohorts, greatly enhancing the statistical power through combined analysis.
In a landmark study, the group combined genetic, clinical, and proteomic data from 30,931 individuals in order to map potential therapeutic targets, using genetic, clinical, and protein data to identify 451 pQTLs. Mendelian Randomization identified 25 protein pathways with causal associations to at least one of the 38 disease and trait phenotypes examined. Of the 25 proteins that appeared to be causal, 14 were already known drug targets (thus validating the method), and the remaining 11 were identified as potential new drug targets.
These findings, particularly the identified molecular pathways associated with various indications, highlight the potential of this data for shaping future pharmaceutical development programs.
SCALLOP Consortium
Get more information about SCALLOP and see a brief video interview with the consortium founder, Dr. Anders Mälarstig (Pfizer & Karolinska Institute).
The UK Biobank Pharma Proteomics Project (UKB-PPP)
The UK Biobank Pharma Proteomics Project (UKB-PPP) is a collaboration between the UK Biobank (UKB) and 13 biopharmaceutical companies to characterize the plasma proteome in over 54,000 UKB participants. The UKB-PPP selected Olink’s PEA technology as its high throughput proteomics platform, utilizing Olink® Explore 3072 to measure nearly 3,000 proteins covering all major biological pathways.
Recent articles, published in Nature by consortium members, have reported on a series of impressive initial findings from the project that demonstrate the astonishing power of combined genomic and proteomic analysis at an unprecedented scale. They also describe a unique open-access data resource for the wider scientific community that will empower a plethora of new discoveries and insights. More details about these articles can be found in our web post,
{kind=link}
eBook
Empowering genomics with high-throughput proteomics
Take this opportunity to stay at the forefront of this groundbreaking field by reading about the latest developments. See how leading scientists are already implementing high-throughput proteomics to shape the future of precision medicine.
Introducing
Olink® Explore HT
Capture true biological insights with proven specificity. At any scale. Perform high-throughput biomarker discovery with ease to gain an understanding of disease at the protein level.
Accelerate your approach to proteomics with Olink® Insight
An open-access online portal that helps you understand and interpret proteomics data for faster insights – includes Visual Pathway Browser and Disease Atlas, Olink Flex Panel builder and panel selection guide, as well as Publication Explorer and Automatic Annotations.